Akhil Perincherry

I am an ML research engineer at Ford Motor Company where I work on computer vision and machine learning for perception features in the context of automated driving. Most of my work is on camera images and LiDAR point clouds.
In my free time I enjoy playing/watching soccer, kickboxing, hiking (waterfall hikes are the best!) and practically any outdoor sport.
Email |
LinkedIn |
Github
Google Scholar |
Twitter
A Simple Framework for Contrastive Learning of Visual Representations - Paper Summary
What
-
This paper looks at contrastive learning of visual representations.
-
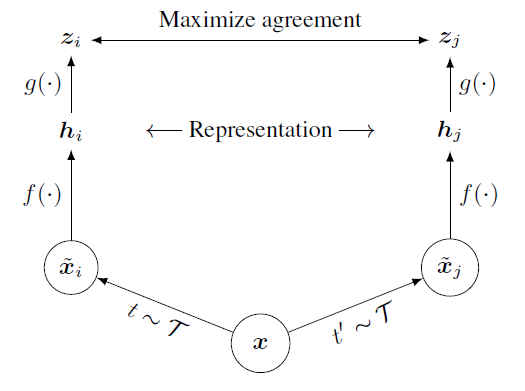
SimCLR learns representations from unlabeled examples by maximizing agreement between differently augmented views of the same data example via a contrastive loss in the latent space.
-
SimCLR achieves 76.5% top-1 accuracy, which is a 7% relative improvement over previous state-of-the-art.
-
When fine-tuned with only 1% of the ImageNet labels, SimCLR achieves 85.8% top-5 accuracy, a relative improvement of 10%.
Method
-
They argue Composition of multiple data augmentation operations is crucial in defining the contrastive prediction tasks that yield effective representations.
-
Training Blocks
- Stochastic data augmentation module
- Random cropping + resize
- Random color distortions
- Random Gaussian Blur
- Base encoder DNN
- ResNet50 with average pooling
- Projection head (small NN)
- MLP with one hidden layer mapping representations to a lower dimensional space where contrastive loss is applied.
- Contrastive Loss function
-
Given a set of augmented pairs including a positive pair, contrastive prediction task aims to identify a positive augmented sample given the other sample in the positive pair amongst the set.
-
Sample N points in a mini-batch -> 2N augmented images which is composed of 2 positive samples and 2(N-1) negative samples. Compute loss function on the prediction task based on this.
-
Update encoder and projection networks to minimize loss. Throw projection network away and use encoder for representations.
-
- Stochastic data augmentation module
Augmentations
-
Geometric - cropping + resizing, rotation, cut-out
-
Appearance - color distortion (color dropping, brightness, contrast, saturation, hue), Gaussian blur, Sobel filtering
-
They state that no single transformation suffices to learn good representations, even though the model can almost perfectly identify the positive pairs in the contrastive task. When composing augmentations, the contrastive prediction task becomes harder, but the quality of representation improves dramatically.
-
One composition of augmentations stands out: random cropping and random color distortion. The problem with using only random cropping as data augmentation is that most patches from an image share a similar color distribution and therefore, color histograms alone suffice to distinguish images. Neural nets could potentially exploit this shortcut to solve the predictive task. Therefore, it is critical to compose cropping with color distortion in order to learn generalizable features.
Evaluation
-
Linear evaluation protocol - Linear classifier is trained on top of the trained encoder network and classification error is used as a proxy for representation quality.
-
They use ResNet50 as base encoder and a 2 layer MLP to project representation to 128 dim latent space.
Takeaways
-
Unsupervised contrastive learning benefits from stronger data augmentation than supervised learning.
-
Gap between supervised models and linear classifiers trained on unsupervised models shrinks as the model size increases, suggesting that unsupervised learning benefits more from bigger models than its supervised counterpart.
-
Furthermore, even when nonlinear projection is used, the layer before the projection head, h, is still much better (>10%) than the layer after, z = g(h), which shows that the hidden layer before the projection head is a better representation than the layer after.
-
They explain that the importance of using the representation before the nonlinear projection is due to loss of information induced by the contrastive loss. In particular, z = g(h) is trained to be invariant to data transformation. Thus, g can remove information that may be useful for the downstream task, such as the color or orientation of objects. By leveraging the nonlinear transformation, more information can be formed and maintained in h.
-
The main differences from their approach to a standard supervised learning on ImageNet is in the choice of data augmentation, use of a nonlinear head at the end of the network, and the loss function.