publications
publications by categories in reversed chronological order.
2025
- CoRL (ORAL)
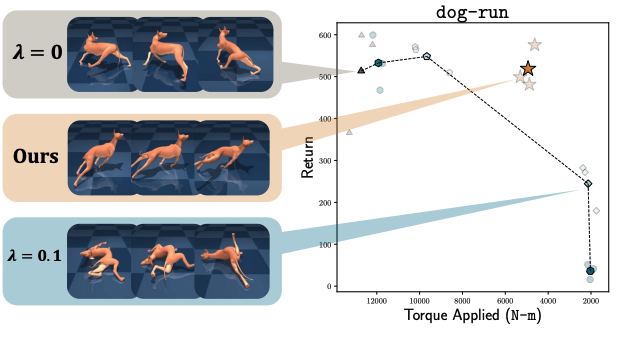 Non-conflicting Energy Minimization in Reinforcement Learning based Robot ControlConference on Robot Learning (CoRL), 2025
Non-conflicting Energy Minimization in Reinforcement Learning based Robot ControlConference on Robot Learning (CoRL), 2025Efficient robot locomotion often requires balancing task performance with energy expenditure. A common approach in reinforcement learning (RL) is to penalize energy use directly in the reward function. This requires carefully weighting the reward terms to avoid undesirable trade-offs where energy minimization harms task success or vice versa. In this work, we propose a hyperparameter-free gradient optimization method to minimize energy without conflicting with task performance. Inspired by recent works in multitask learning, our method applies policy gradient projection between task and energy objectives to promote non-conflicting updates. We evaluate this technique on standard locomotion benchmarks of DM-Control and HumanoidBench and demonstrate a reduction of 64% energy usage while maintaining comparable task performance. Further, we conduct experiments on a Unitree GO2 quadruped showcasing Sim2Real transfer of energy efficient policies. Our method is easy to implement in standard RL pipelines with minimal code changes, and offers a principled alternative to reward shaping for energy efficient control policies.
@article{PEGRAD, author = {Peri, Skand and Perincherry, Akhil and Pandit, Bikram and Lee, Stefan}, title = {Non-conflicting Energy Minimization in Reinforcement Learning based Robot Control}, journal = {Conference on Robot Learning (CoRL)}, year = {2025}, } - CVPR
 Do Visual Imaginations Improve Vision-and-Language Navigation Agents?Akhil Perincherry, Jacob Krantz, and Stefan LeeIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025
Do Visual Imaginations Improve Vision-and-Language Navigation Agents?Akhil Perincherry, Jacob Krantz, and Stefan LeeIn Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025Vision-and-Language Navigation (VLN) agents are tasked with navigating an unseen environment using natural language instructions. In this work, we study if visual representations of sub-goals implied by the instructions can serve as navigational cues and lead to increased navigation performance. To synthesize these visual representations or “imaginations”, we leverage a text-to-image diffusion model on landmark references contained in segmented instructions. These imaginations are provided to VLN agents as an added modality to act as landmark cues and an auxiliary loss is added to explicitly encourage relating these with their corresponding referring expressions. Our findings reveal an increase in success rate (SR) of ∼1 point and up to ∼0.5 points in success scaled by inverse path length (SPL) across agents. These results suggest that the proposed approach reinforces visual understanding compared to relying on language instructions alone.
@inproceedings{aperinch_2025_VLN_Imagine, title = {Do Visual Imaginations Improve Vision-and-Language Navigation Agents?}, author = {Perincherry, Akhil and Krantz, Jacob and Lee, Stefan}, booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)}, year = {2025}, } - ICCV
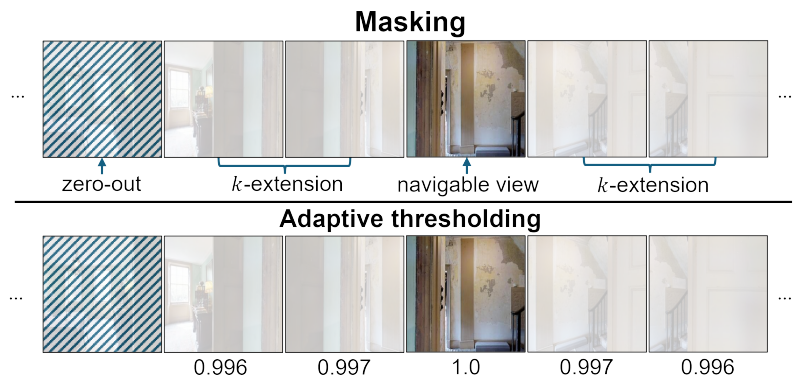 Harnessing Input-adaptive Inference for Efficient VLNDongwoo Kang, Akhil Perincherry, Zachary Coalson, and 3 more authorsIn International Conference on Computer Vision (ICCV), 2025
Harnessing Input-adaptive Inference for Efficient VLNDongwoo Kang, Akhil Perincherry, Zachary Coalson, and 3 more authorsIn International Conference on Computer Vision (ICCV), 2025An emerging paradigm in vision-and-language navigation (VLN) is the use of history-aware multi-modal transformer models. Given a language instruction, these models process observation and navigation history to predict the most appropriate action for an agent. While they have significantly improved performance, the scale of these models can be a bottleneck in practical settings with limited computational resources. In this work, we propose a novel input-adaptive navigation method to enhance VLN model efficiency. We first show that existing input-adaptive mechanisms fail to reduce computations without substantial performance degradation. To address this, we introduce three adaptive algorithms, each deployed at a different level: (1) To improve spatial efficiency, we selectively process panoramic views at each observation of an agent. (2) To improve intra-model efficiency, we propose importance-based adaptive thresholding for the early-exit methods. (3) To improve temporal efficiency, we implement a caching mechanism that prevents reprocessing of views previously seen by the agent. In evaluations on seven VLN benchmarks, we demonstrate over a 2x reduction in computation across three off-the-shelf agents in both standard and continuous environments.
@inproceedings{kang2025efficientvln, author = {Kang, Dongwoo and Perincherry, Akhil and Coalson, Zachary and Gabriel, Aiden and Lee, Stefan and Hong, Sanghyun}, title = {Harnessing Input-adaptive Inference for Efficient VLN}, booktitle = {International Conference on Computer Vision (ICCV)}, year = {2025}, }
2024
- 3DV
 Geometry-guided cross-view diffusion for one-to-many cross-view image synthesisTao Jun Lin, Wenqing Wang, Yujiao Shi, and 3 more authorsInternational Conference on 3D Vision (3DV), 2024
Geometry-guided cross-view diffusion for one-to-many cross-view image synthesisTao Jun Lin, Wenqing Wang, Yujiao Shi, and 3 more authorsInternational Conference on 3D Vision (3DV), 2024This paper presents a novel approach for cross-view synthesis aimed at generating plausible ground-level images from corresponding satellite imagery or vice versa. We refer to these tasks as satellite-to-ground (Sat2Grd) and ground-to-satellite (Grd2Sat) synthesis, respectively. Unlike previous works that typically focus on one-to-one generation, producing a single output image from a single input image, our approach acknowledges the inherent one-to-many nature of the problem. This recognition stems from the challenges posed by differences in illumination, weather conditions, and occlusions between the two views. To effectively model this uncertainty, we leverage recent advancements in diffusion models. Specifically, we exploit random Gaussian noise to represent the diverse possibilities learnt from the target view data. We introduce a Geometry-guided Cross-view Condition (GCC) strategy to establish explicit geometric correspondences between satellite and street-view features. This enables us to resolve the geometry ambiguity introduced by camera pose between image pairs, boosting the performance of cross-view image synthesis. Through extensive quantitative and qualitative analyses on three benchmark cross-view datasets, we demonstrate the superiority of our proposed geometry-guided cross-view condition over baseline methods, including recent state-of-the-art approaches in cross-view image synthesis. Our method generates images of higher quality, fidelity, and diversity than other state-of-the-art approaches.
@article{lin2024geometry, title = {Geometry-guided cross-view diffusion for one-to-many cross-view image synthesis}, author = {Lin, Tao Jun and Wang, Wenqing and Shi, Yujiao and Perincherry, Akhil and Vora, Ankit and Li, Hongdong}, journal = {International Conference on 3D Vision (3DV)}, year = {2024}, } - ECCV
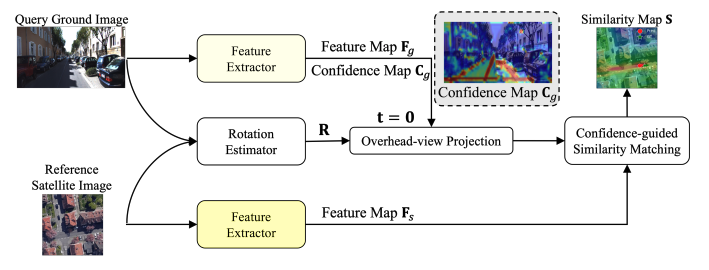 Weakly-supervised camera localization by ground-to-satellite image registrationIn European Conference on Computer Vision (ECCV), 2024
Weakly-supervised camera localization by ground-to-satellite image registrationIn European Conference on Computer Vision (ECCV), 2024The ground-to-satellite image matching/retrieval was initially proposed for city-scale ground camera localization. This work addresses the problem of improving camera pose accuracy by ground-to-satellite image matching after a coarse location and orientation have been obtained, either from the city-scale retrieval or from consumer-level GPS and compass sensors. Existing learning-based methods for solving this task require accurate GPS labels of ground images for network training. However, obtaining such accurate GPS labels is difficult, often requiring an expensive \colorblackReal Time Kinematics (RTK) setup and suffering from signal occlusion, multi-path signal disruptions, \etc. To alleviate this issue, this paper proposes a weakly supervised learning strategy for ground-to-satellite image registration when only noisy pose labels for ground images are available for network training. It derives positive and negative satellite images for each ground image and leverages contrastive learning to learn feature representations for ground and satellite images useful for translation estimation. We also propose a self-supervision strategy for cross-view image relative rotation estimation, which trains the network by creating pseudo query and reference image pairs. Experimental results show that our weakly supervised learning strategy achieves the best performance on cross-area evaluation compared to recent state-of-the-art methods that are reliant on accurate pose labels for supervision.
@inproceedings{shi2024weakly, title = {Weakly-supervised camera localization by ground-to-satellite image registration}, author = {Shi, Yujiao and Li, Hongdong and Perincherry, Akhil and Vora, Ankit}, booktitle = {European Conference on Computer Vision (ECCV)}, pages = {39--57}, year = {2024}, organization = {Springer}, } - ICRA
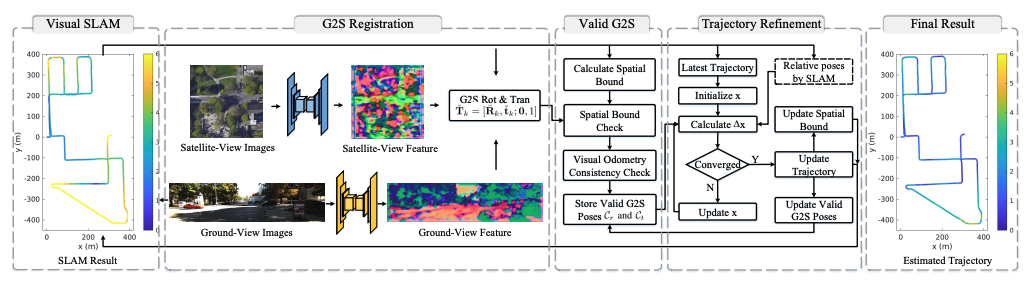 Increasing slam pose accuracy by ground-to-satellite image registrationIn 2024 IEEE International Conference on Robotics and Automation (ICRA), 2024
Increasing slam pose accuracy by ground-to-satellite image registrationIn 2024 IEEE International Conference on Robotics and Automation (ICRA), 2024Vision-based localization for autonomous driving has been of great interest among researchers. When a pre-built 3D map is not available, the techniques of visual simultaneous localization and mapping (SLAM) are typically adopted. Due to error accumulation, visual SLAM (vSLAM) usually suffers from long-term drift. This paper proposes a framework to increase the localization accuracy by fusing the vSLAM with a deep-learning-based ground-to-satellite (G2S) image registration method. In this framework, a coarse (spatial correlation bound check) to fine (visual odometry consistency check) method is designed to select the valid G2S prediction. The selected prediction is then fused with the SLAM measurement by solving a scaled pose graph problem. To further increase the localization accuracy, we provide an iterative trajectory fusion pipeline. The proposed framework is evaluated on two well-known autonomous driving datasets, and the results demonstrate the accuracy and robustness in terms of vehicle localization.
@inproceedings{zhang2024increasing, title = {Increasing slam pose accuracy by ground-to-satellite image registration}, author = {Zhang, Yanhao and Shi, Yujiao and Wang, Shan and Vora, Ankit and Perincherry, Akhil and Chen, Yongbo and Li, Hongdong}, booktitle = {2024 IEEE International Conference on Robotics and Automation (ICRA)}, pages = {8522--8528}, year = {2024}, organization = {IEEE}, }
2023
- ICCV
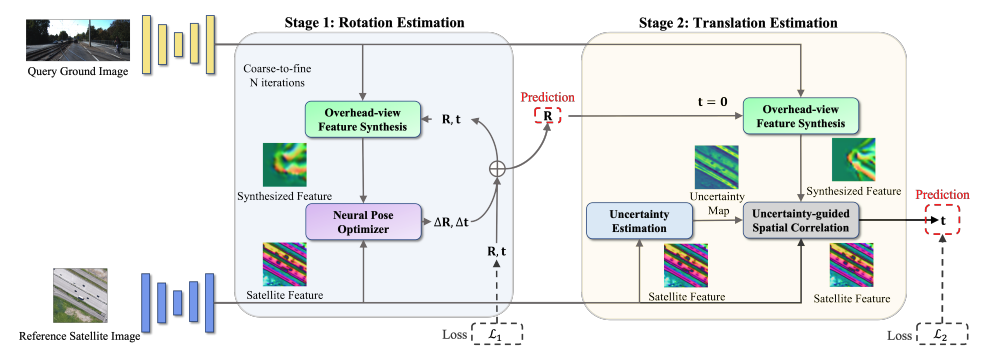 Boosting 3-dof ground-to-satellite camera localization accuracy via geometry-guided cross-view transformerYujiao Shi, Fei Wu, Akhil Perincherry, and 2 more authorsIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
Boosting 3-dof ground-to-satellite camera localization accuracy via geometry-guided cross-view transformerYujiao Shi, Fei Wu, Akhil Perincherry, and 2 more authorsIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023Image retrieval-based cross-view localization methods often lead to very coarse camera pose estimation, due to the limited sampling density of the database satellite images. In this paper, we propose a method to increase the accuracy of a ground camera’s location and orientation by estimating the relative rotation and translation between the ground-level image and its matched/retrieved satellite image. Our approach designs a geometry-guided cross-view transformer that combines the benefits of conventional geometry and learnable cross-view transformers to map the ground-view observations to an overhead view. Given the synthesized overhead view and observed satellite feature maps, we construct a neural pose optimizer with strong global information embedding ability to estimate the relative rotation between them. After aligning their rotations, we develop an uncertainty-guided spatial correlation to generate a probability map of the vehicle locations, from which the relative translation can be determined. Experimental results demonstrate that our method significantly outperforms the state-of-the-art. Notably, the likelihood of restricting the vehicle lateral pose to be within 1m of its Ground Truth (GT) value on the cross-view KITTI dataset has been improved from 35.54% to 76.44%, and the likelihood of restricting the vehicle orientation to be within 1∘ of its GT value has been improved from 19.64% to 99.10%.
@inproceedings{shi2023boosting, title = {Boosting 3-dof ground-to-satellite camera localization accuracy via geometry-guided cross-view transformer}, author = {Shi, Yujiao and Wu, Fei and Perincherry, Akhil and Vora, Ankit and Li, Hongdong}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, pages = {21516--21526}, year = {2023}, } - ICCV
 View consistent purification for accurate cross-view localizationIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023
View consistent purification for accurate cross-view localizationIn Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), 2023This paper proposes a fine-grained self-localization method for outdoor robotics that utilizes a flexible number of onboard cameras and readily accessible satellite images. The proposed method addresses limitations in existing cross-view localization methods that struggle to handle noise sources such as moving objects and seasonal variations. It is the first sparse visual-only method that enhances perception in dynamic environments by detecting view-consistent key points and their corresponding deep features from ground and satellite views, while removing off-the-ground objects and establishing homography transformation between the two views. Moreover, the proposed method incorporates a spatial embedding approach that leverages camera intrinsic and extrinsic information to reduce the ambiguity of purely visual matching, leading to improved feature matching and overall pose estimation accuracy. The method exhibits strong generalization and is robust to environmental changes, requiring only geo-poses as ground truth. Extensive experiments on the KITTI and Ford Multi-AV Seasonal datasets demonstrate that our proposed method outperforms existing state-of-the-art methods, achieving median spatial accuracy errors below 0.5 meters along the lateral and longitudinal directions, and a median orientation accuracy error below 2 degrees.
@inproceedings{wang2023view, title = {View consistent purification for accurate cross-view localization}, author = {Wang, Shan and Zhang, Yanhao and Perincherry, Akhil and Vora, Ankit and Li, Hongdong}, booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)}, pages = {8197--8206}, year = {2023}, }
2022
- ICRA
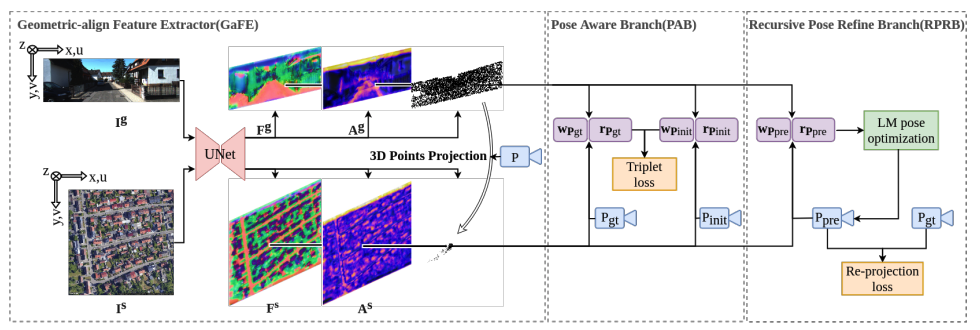 Satellite image based cross-view localization for autonomous vehicle2023 IEEE International Conference on Robotics and Automation (ICRA), 2022
Satellite image based cross-view localization for autonomous vehicle2023 IEEE International Conference on Robotics and Automation (ICRA), 2022Existing spatial localization techniques for autonomous vehicles mostly use a pre-built 3D-HD map, often constructed using a survey-grade 3D mapping vehicle, which is not only expensive but also laborious. This paper shows that by using an off-the-shelf high-definition satellite image as a ready-to-use map, we are able to achieve cross-view vehicle localization up to a satisfactory accuracy, providing a cheaper and more practical way for localization. While the utilization of satellite imagery for cross-view localization is an established concept, the conventional methodology focuses primarily on image retrieval. This paper introduces a novel approach to cross-view localization that departs from the conventional image retrieval method. Specifically, our method develops (1) a Geometric-align Feature Extractor (GaFE) that leverages measured 3D points to bridge the geometric gap between ground and overhead views, (2) a Pose Aware Branch (PAB) adopting a triplet loss to encourage pose-aware feature extraction, and (3) a Recursive Pose Refine Branch (RPRB) using the Levenberg-Marquardt (LM) algorithm to align the initial pose towards the true vehicle pose iteratively. Our method is validated on KITTI and Ford Multi-AV Seasonal datasets as ground view and Google Maps as the satellite view. The results demonstrate the superiority of our method in cross-view localization with median spatial and angular errors within 1 meter and 1∘, respectively.
@article{wang2022satellite, title = {Satellite image based cross-view localization for autonomous vehicle}, author = {Wang, Shan and Zhang, Yanhao and Vora, Ankit and Perincherry, Akhil and Li, Hongdong}, journal = {2023 IEEE International Conference on Robotics and Automation (ICRA)}, year = {2022}, }