Akhil Perincherry

Hello! I am a PhD. student at Oregon State University with Dr. Stefan Lee working generally in visual-language grounding and embodied AI. I am also an ML engineer at Ford Motor Company working primarily on perception features for automated driving mostly using camera images and LiDAR point clouds.
In my free time (404), I enjoy playing/watching soccer, kickboxing, hiking (esp. waterfall hikes) and practically any outdoor sport.
Email |
LinkedIn |
Github
Google Scholar |
Twitter
Contrastive Training for Improved Out-of-Distribution Detection - Paper Summary
What
-
They investigate use of contrastive learning in OOD detection without needing data explicitly labeled as OOD. They introduce CLP score to quantify difficulty of OOD detection by capturing similarity of inlier and outlier datasets. Their method makes a distinction between near and far OOD classes and improves performance in near OOD classes.
-
Uses SimCLRv1 as the contrastive learning framework.
Existing techniques
-
Out-of-distribution detection can be performed by approximating a probability density p(x) of training inputs x, and detecting test-time OOD inputs using a threshold; if p(x) < threshold, x is considered OOD.
-
An intuitive strategy for detecting OOD samples is to train a generative model from which one can compute the likelihood as an OOD score. However, applying generative models directly to the image space in OOD detection has not achieved state of the art results, even when combined with a classification network.
-
Modern OOD detection techniques instead assign a scalar score s(z) (e.g. via an approximated probability density) to activations z in an intermediate feature space of a discriminatively trained classifier f, and use that to detect OOD inputs. The success of these approaches highly depends on the quality of the intermediate feature space defined by f.
Idea
-
If the feature space is not sufficiently rich, the network may be blind to properties of the image that turn out to be necessary for detection of OOD inputs. Consider, for instance, the case of visual inputs. Variation in captured images is either due to semantic differences of the objects (e.g. pose, shape, texture), or due to differences in the imaging process (e.g. lighting, camera position). Depending on the application, an unfamiliar variation of either type could lead to an input being deemed out-of-distribution. We therefore desire intermediate feature spaces defined by f to capture as many semantic properties as possible, while also remaining sensitive to properties of the imaging process.
-
Supervised learning produces semantic representations, but only to the extent that those representations discriminate between classes labeled in the dataset. The network f is not incentivized to learn features (semantic or otherwise) beyond the bare minimum necessary to classify. Current state-of-the-art approaches to OOD detection enrich the intermediate feature space beyond what would ordinarily be learned via only supervised learning on the inlier dataset.
-
The key idea of this paper is to encourage f to learn as many high-level, task-agnostic, semantic features as possible from the in-distribution dataset, so as to enable it to detect any kind of out-of-distribution input at test time.
-
Contrastive training shapes z (activations in penultimate layer of f) to be sensitive to capture information relevant for OOD detection. They rely on having a richer representation to define the distribution.
-
Using a set of class-preserving transformations, SimCLR introduces a loss that pulls transformed versions of the same image closer to each other, whilst pushing all other images away. This incentivizes the model to learn features that discriminate between all dataset images, even if they belong to the same class. When combined with supervised training, f learns features that are both rich and semantically discriminative.
-
They distinguish between near OOD regimes where inlier and outlier distributions are meaningfully similar, and far OOD regimes where the two are unrelated. Near OOD is encountered more often in practice, e.g. (from the paper) - a system that detects medical pathologies will often encounter patients with atypical combinations of pathologies (near OOD) and will have to be reliable nonetheless. A completely broken sensor (far OOD) is less prevalent by comparison. Consequently, they advocate for quantification of the ‘similarity’ of inlier and outlier distributions used in evaluations, and propose a metric.
-
For image classification, camera parameter and illumination are obvious variations. Both can be approximated by translating, scaling and rotating the image, as well as applying brightness and contrast transformations.
Method
- They avoid explicit inlier and outlier density modelling in the input space.
- They don’t require access to data from the outlier distribution during training or tuning.
- They use Confusion Log Probability (CLP) as a metric to evaluate OOD detection methods, which measures the similarity of inlier / outlier dataset pairs.
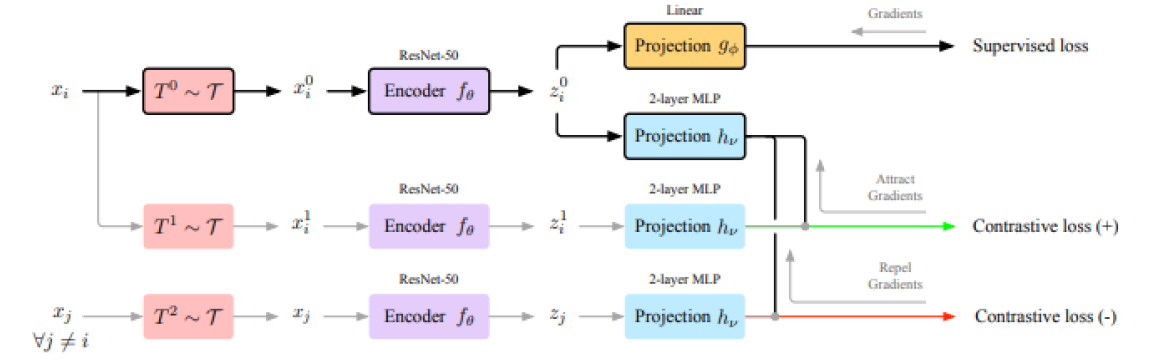
-
Architecture is similar to SimCLR with an encoder network. It has two projection heads - one for mapping to class predictions and the other for mapping to a low dimensional embedding over which contrastive loss is defined.
-
Only IID samples are used in training. In the first stage of training, only contrastive loss is used for a large number of epochs to learn representations. The class loss is added much later for a small number of epochs.
-
A Gaussian distribution is fit to the activations (lower dimensional embedding from the projection network).
-
Contrastive loss encourages the network to encode all features capable of distinguishing between samples rather than only those necessary to discriminate between classes.
-
To simplify the distribution of the activation that is fitted, label smoothing is added to the cross-entropy loss, so as to prevent the network from spreading out the activations in an attempt to drive the logits of the correct class to infinity. This encourages tight clustering of the activations of each class.
-
Therefore, they perform density estimation class-wise, over the activations z at the penultimate layer. For each class c, an n-dimensional multivariate Gaussian is estimated with n being the dimension of z. For the OOD score s(x), the highest density is taken over all the class-conditional Gaussian components. A high score s(x) indicates that the representation of a test sample in the embedding space lies close to the typical set for one of the classes. Conversely, a low score signifies that the test sample has a representation that is far from all training set examples and is therefore likely to represent an OOD example.
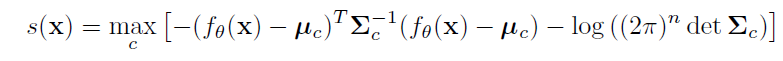
CLP score
- Need for CLP
- Real world test samples may vary strongly, from falling exactly within the training distribution to falling far out of the training distribution. As a consequence, a robust model should exhibit strong OOD detection performance across the entirety of the spectrum. Current benchmarks however report only a single performance statistic for each in-distribution and OOD dataset pair, such as the area under the receiver operating characteristic curve. This type of evaluation metric can therefore not resolve the performance in detecting near versus far OOD. The openness score, used in the Open Set Recognition community, gives a difficulty measure based on the number of classes in the training set compared to the number of classes in the test set. This measure, however, ignores the visual similarity that can exist between classes, and therefore the relative difficulty of detecting different unknown classes.
- confusion log probability (CLP) is a measure of the difficulty of an OOD detection task. CLP is based on the probability with which a classifier confuses outliers with inliers, where the classifier has access to outlier samples during training.

- A low CLP indicates that test samples are far OOD and a high CLP indicates that they are near OOD. By using classifiers to estimate class confusions, they ground the measure in a notion of visual similarity rather than semantic or image space similarity.
Conclusion
They showed that representations obtained through contrastive training improve OOD detection performance beyond what is possible with purely supervised training. The representations are shaped by joint training, in which the contrastive loss pushes the representations apart, even within each class, while the supervised loss acts to cluster the representations by class.