Akhil Perincherry

Hello! I am a PhD. student at Oregon State University with Dr. Stefan Lee working generally in visual-language grounding and embodied AI. I am also an ML engineer at Ford Motor Company working primarily on perception features for automated driving mostly using camera images and LiDAR point clouds.
In my free time (404), I enjoy playing/watching soccer, kickboxing, hiking (esp. waterfall hikes) and practically any outdoor sport.
Email |
LinkedIn |
Github
Google Scholar |
Twitter
Zero-Shot Text-to-Image Generation - Paper Summary
Method
-
A transformer is trained autoregressively to model images and text as a single stream of data. Their method consists of a discrete VAE (dVAE) and an autoregressive transformer.
-
A discrete VAE is trained to compress 256x256x3 image into 32x32 grid of image tokens. The tokens are chosen from amongst 8192 (vocabulary size) different tokens (vectors). Directly using pixels is computationally infeasible which motivates the use of dVAE. However, due to this, dVAE results tend to be blurry since it cannot model high frequency details very well. Image is encoded into discrete tokens which are then used in image reconstruction.
-
256 text tokens and 1024 (32x32) image tokens are concatenated over which a transformer is trained in an autoregressive manner. In other words, given the text tokens, the first image token is sampled which is fed to the input of the transformer along with the earlier input and then the second image token is sampled and so on. This is repeated until all the 1024 tokens are generated. From an initial 256 tokens, the model will autocomplete the remaining image tokens which form the data stream, from which the generated image can be rendered.
-
The generated 1024 image tokens (this forms the latent indices) are looked up using the codebook and the resulting codebook vectors are fed to the dVAE decoder to generate the image.
-
By sampling new latent sequences from the output of the transformer, new images can be generated by the dVAE decoder.
Details
-
Unlike VQ-VAE, which picks one vector deterministically from the codebook (usually the closest l2 distance to the encoded latent), dVAE encoder outputs a distribution over codebook vector for each latent.
-
Since discrete sampling is non-differentiable, the method employ Gumbel softmax relaxation. This relaxes the discrete sampling problem to a continuous approximation.
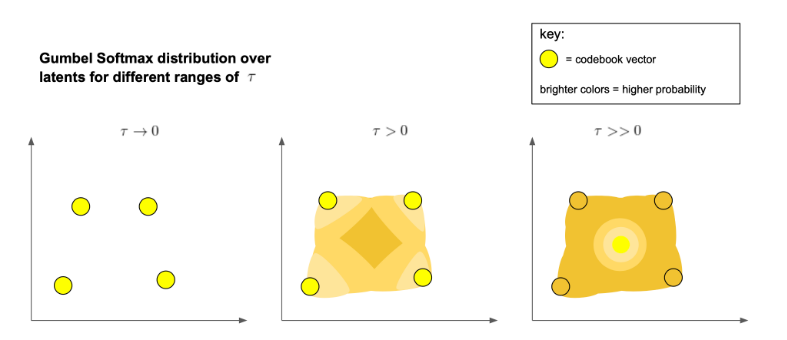
- Gumbel softmax relaxation in the context of DALL-E is explained well here. Basically, the Gumbel softmax equation is reduced to a differentiable operation by changing argmax to softmax which outputs a grid of probabilities/weights. The resulting sampled latent vector will be a weighted sum of the codebook vector from the obtained weights rather than one specific codebook vector like in VQ-VAE.
- They introduce a hyperparameter tau (temperature) which reduces to discrete sampling as it tends to zero and as it approaches 1, a deterministic distribution is obtained which reduces to the centroid of the codebook vectors. The temperature parameter is reduced throughout the training towards an approximate discrete sampling.
 (image source: https://ml.berkeley.edu/blog/posts/dalle2/)
(image source: https://ml.berkeley.edu/blog/posts/dalle2/)
- They introduce a hyperparameter tau (temperature) which reduces to discrete sampling as it tends to zero and as it approaches 1, a deterministic distribution is obtained which reduces to the centroid of the codebook vectors. The temperature parameter is reduced throughout the training towards an approximate discrete sampling.
- The training is performed in two stages
-
Initially, an ELBO objective (standard VAE objective) is optimized i.e. the image reconstruction and the encoding following the Gumbel softmax relaxation. The latent distribution prior is taken to be a uniform distribution over the codebook vectors.
-
In the second stage, dVAE encoder and decoder is fixed and the prior over the latents is learned using the autoregressive transformer described earlier using image-text pairs.
-
-
The transformer is a decoder only model where each image token can attend to any text tokens in its self-attention layers.
-
During sample generation, they use their contrastive learning model CLIP which assigns score to a given caption and image pair that tells how well they match. Based on this, the best match is outputted.
- Typically l1 and l2 reconstruction objectives are used in VAEs which correspond to Laplace and Gaussian distributions. However, they don’t make sense while modeling pixels since pixel ranges between 0 to 1 while these distributions are non-zero beyond this range. The authors define a variant of Laplace distribtution that constraints the range between 0 to 1 by considering the pdf of the random variable obtained after applying sigmoid function to a Laplace random variable. They call this the logit-Laplace distribution.