Akhil Perincherry

I am an ML research engineer at Ford Motor Company where I work on computer vision and machine learning for perception features in the context of automated driving. Most of my work is on camera images and LiDAR point clouds.
In my free time I enjoy playing/watching soccer, kickboxing, hiking (waterfall hikes are the best!) and practically any outdoor sport.
Email |
LinkedIn |
Github
Google Scholar |
Twitter
Aim
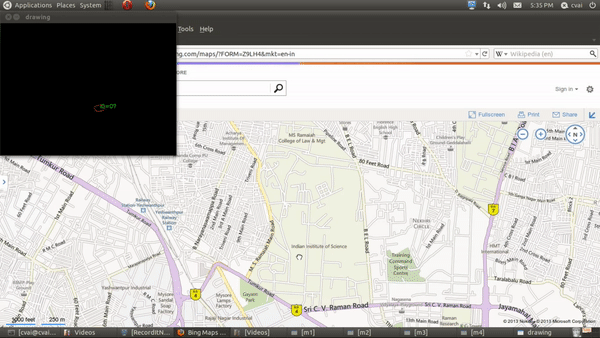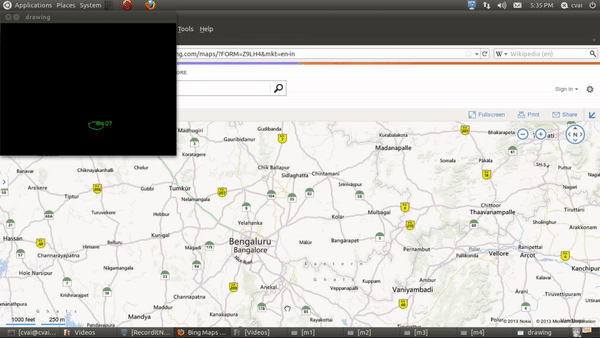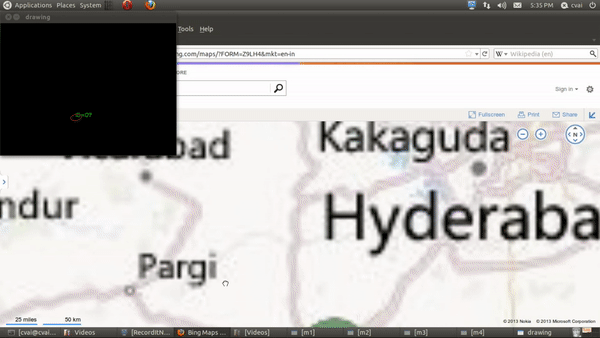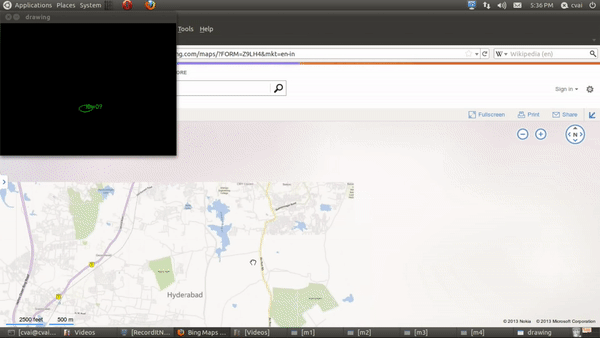
My primary work was to develop a table-top touch interface using a projector-camera setup. The aim of this project is to use projector camera systems for touch based interactions. In one working pipeline, a text document is projected onto a flat table-top and the user can interact with the document using his/her fingers. The user can touch an area of the table corresponding to a projected word, and that word is converted to audio or the google search corresponding to the work is opened. In another working, Google maps page is projected onto the table, and the user can simulate mouse action using fingers to zoom in/out, move etc.

Motivation
Such systems are cheaper than existing systems and can be scaled at with little rise in cost. They can also be used on curved and nonlinear surfaces without changing the hardware in anyway. Also the size of the setup remains the same even as the size of the display increases making them much less bulkier and more portable than existing systems.
Set-up





Working
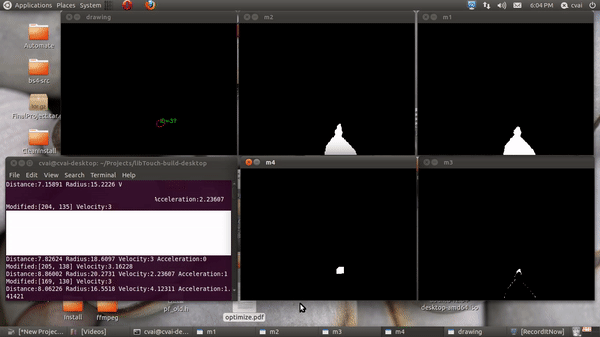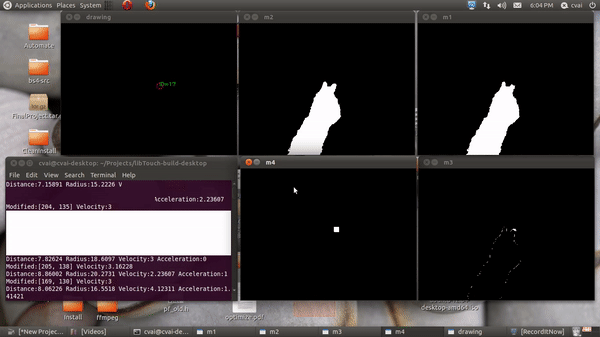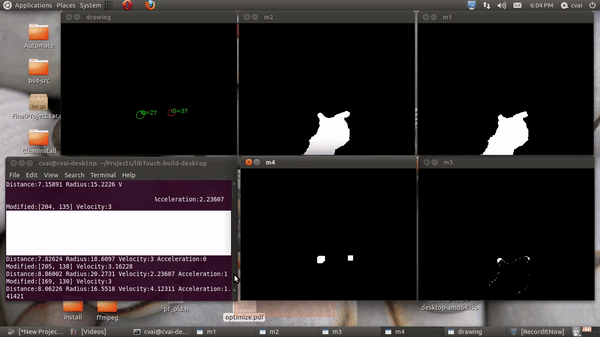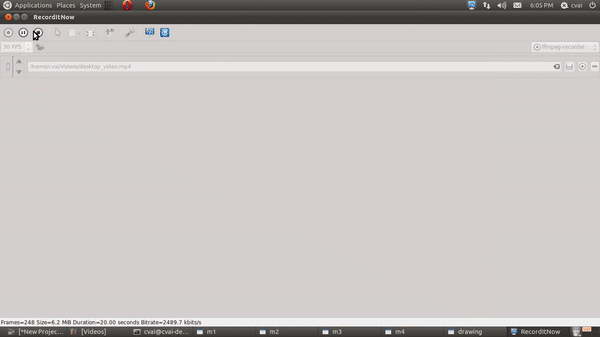
The projector in the projector camera pair acts as the display and the camera is used as an input device. The depth of the fingers was obtained using Kinect’s depth sensor, and the finger locations was extracted using image processing operations. To elaborate, a static image was taken during the start of the run and using background subtraction, the finger masks were obtained. Contours were fitted onto this resulting masks, and an ellipse was fit onto each of the fingertip. The blobs/ellipses corresponding to the finger contact points are tracked using distance-based association. The region of the document corresponding to the finger position is extracted using planar transformation and sent to an OCR and then a Text To Speech (TTS) engine or a Google search engine.
A couple of unforeseen problems I faced during this work was the weight of the projector was causing the stand holding the projector-camera setup to bend which would mess up the manual depth calibration. The air pockets under the sheet on the table serving as a touch pad also led to change in depth values from what was set-up initially. To alleviate this, depth calibration was done automatically each time the setup is kick-started by finding a flat plane and estimating it’s depth, and then using this as the depth of the touch pad rather than relying on manually set values.