Akhil Perincherry

Hello! I am a PhD. student at Oregon State University with Dr. Stefan Lee working generally in visual-language grounding and embodied AI. I am also an ML engineer at Ford Motor Company working primarily on perception features for automated driving mostly using camera images and LiDAR point clouds.
In my free time (404), I enjoy playing/watching soccer, kickboxing, hiking (esp. waterfall hikes) and practically any outdoor sport.
Email |
LinkedIn |
Github
Google Scholar |
Twitter
BEIT: BERT Pre-Training of Image Transformers - Paper Summary
Introduction
-
This paper addresses the data hungry problem with transformers using self-supervised learning to pre-train vision transformers via denoising auto-encoding framework.
-
They take inspiration from the masked language modeling (MLM) used in BERT to pre-train models. An image is split into patches which are tokenized. A subset of image patches are masked randomly and fed to a transformers whose objective is to recover visual tokens from the corrupted patches. They call this Masked Image Modeling (MIM).
-
They observe better results using this strategy compared to DEiT which trains from scratch on ImageNet-1K dataset.
-
The patches are tokenized to discrete visual tokens using the latent code of the discrete VAE developed in DALL-E (publicly available).
-
The authors state that predicting raw pixels instead of visual tokens in the pre-training task is inefficient as it wastes modeling capability on short-range dependencies and high frequency details. This opposes the wisdom used in another popular work that came out much later Masked Autoencoders are scalable vision learners.
Method
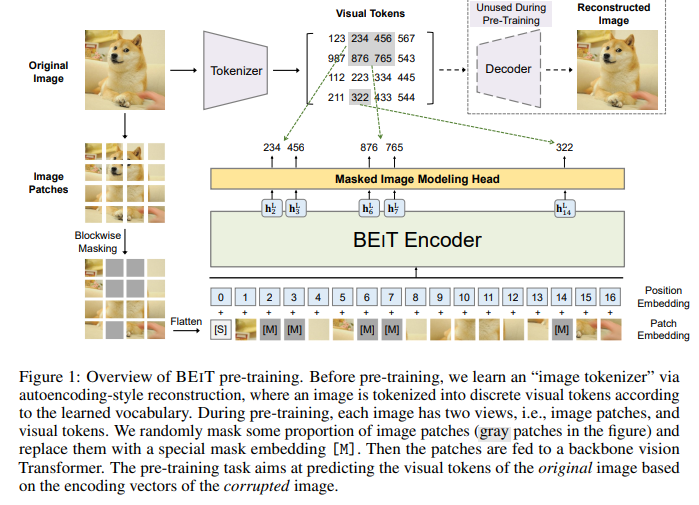
-
224x224 sized images are split into patches where each patch is 16x16. The patches are processed in an identical manner to ViT to obtain input embeddings.
- The image is tokenized using a learned image tokenizer via a discrete VAE (dVAE) framework developed in DALL-E. Visual token learning consists of a tokenizer and a decoder.
- Tokenizer maps pixels to discrete latent codes from a vocabulary/visual code-book of size 8192.
- Decoder is trained to reconstruct input image based on visual tokens.
-
Note that since the latent tokens are discrete, the model training is non-differentiable. This is alleviated using Gumbel-softmax relaxation used in DALL-E.
- A sequence of image patches are fed to the transformer, which are linearly projected to obtain patch embeddings. Learnable 1D positional encodings are added to the embeddings. Last layer of the transformer is used as the encoded image patch representations.
Pre-training using MIM
-
Input image is split into image patches where each patch is tokenized into a visual token. Around 40% of the input patches are masked randomly and replaced with a learnable embedding. The masked patches are inputted into the transformer block and its final layer output is taken as the encoded representation. For each masked position, a softmax classifier is used to predict it’s visual token.
-
The author’s state that their MIM can be viewed as a VAE where the evidence lower bound (ELBO) of recovering original image from its masked version is:

- The model is learned in 2 stages -
- First, image tokenizer is obtained using dVAE by minimizing the reconstruction loss (reconstructing from latent code) using a uniform prior.
- Then, MIM pre-training task prior is learned by keeping tokenizer and the decoder fixed.
- Random resized cropping, horizontal flipping and color jittering techniques are used in their augmentation policy.
Results
-
After pre-training, a task layer is inserted on the transformer and the parameters are fine-tuned leveraging the common pre-training-then-finetuning paradigm used in SimCLR etc. The downstream tasks employed here are image classification and semantic segmentation.
-
Image classification - Patch encoded representations are averaged (average pooling) and fed to a softmax classifier. Parameters of BEIT and softmax layers are both updated in fine-tuning.
-
Segmentation - Pre-trained BEIT is used as a backbone encoder and several deconvolution layers are added to form the decoder. The model is fine-tuned end-to-end.
-
Intermediate finetuning - After pre-training, BEIT can be further trained on data-rich intermediate datasets like ImageNet before finetuning on downstream tasks.
-
After finetuning the model with 224x224, they additionally finetune the model with 384x384 images for 10 more epochs following the strategy used in DeiT.
-
The authors observe that BEIT tends to help more for extremely larger models (such as 1B, or 10B), especially when labeled data are insufficient to conduct supervised pre-training for such large models. The paper references Zhai et al. (2021) report that states supervised pre-training of a 1.8B-size vision Transformer requires billions of labeled images.
-
When the authors modeled the problem as a pixel regression task instead of predicting masked patches, they observe worse results thus concluding that visual token prediction is crucial to BEIT. However, the MAE work in the future contradicts this partially.