Akhil Perincherry

Hello! I am a PhD. student at Oregon State University with Dr. Stefan Lee working generally in visual-language grounding and embodied AI. I am also an ML engineer at Ford Motor Company working primarily on perception features for automated driving mostly using camera images and LiDAR point clouds.
In my free time (404), I enjoy playing/watching soccer, kickboxing, hiking (esp. waterfall hikes) and practically any outdoor sport.
Email |
LinkedIn |
Github
Google Scholar |
Twitter
Masked Autoencoders Are Scalable Vision Learners - Paper Summary
Introduction
-
This paper (like BEIT) studies the application of self-supervised learning used typically in NLP to vision space. Specifically, the papers propose the idea of masked autoencoders for pre-training vision models and show that they’re scalable.
-
Masked autoencoding refers to removing a portion of data and asking the model to predict the removed content, thus facilitating learning large generalizable models.
-
Differences between masked autoencoding in vision and language:
- Convolutions operate in regular grids unlike language networks which makes integrating mask tokens (indicator functions), positional encodings difficult. This was solved with the advent of ViT.
- Languages are dense highly semantic human generated signals. In solving tasks like masked language modeling (MLM), the model is forced to learn language understanding. Images are natural signals with significant spatial redundancy i.e. it is not difficult to predict a pixel value from looking at its neighbors’ values with little understanding of semantic content in the scene. The authors propose to alleviate this by masking a very high portion of patches randomly. If very low amount of masking is done, the model can get away with very little semantic understanding leveraging spatial redundancy.
- In vision, the decoder in the autoencoder reconstructs pixels which is a low semantic level task compared to recognition. In language, the decoder’s task of predicting missing words involves rich semantic information and thus the decoder used can be trivial. In vision, the decoder design is crucial to achieve adequate semantic information in the learned latent representations.
Method
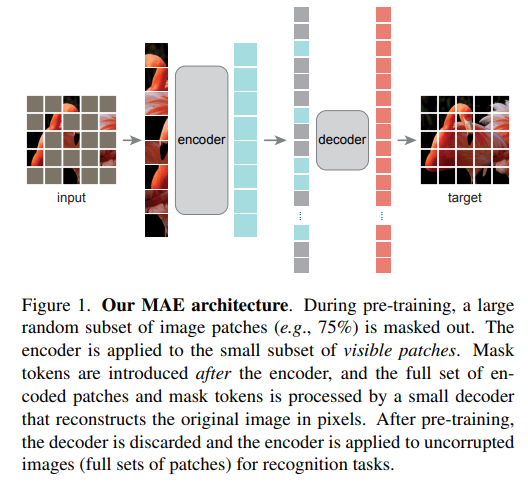
-
Based on the above observations, the authors propose a asymmetric masked auto encoding approach. To elaborate, the image is split into patches that are masked (high ratio of masking) randomly. The encoder is fed only patches that are visible (without mask tokens). A lightweight decoder is given the encodings of the visible patches along with the masked tokens and is tasked to reconstruct the original image in pixel level.
-
They use random sampling (with a high masking ratio) without replacement following a uniform distribution. Uniform distribution prevents a center bias i.e. having more of masking around the image center.
-
They use ViT as the encoder which is applied only on the visible or unmasked patches. Since masked patches are removed i.e. no masked tokens, the transformer encoder operates on roughly around 25% of the image, large encoders can be trained with very little compute and memory.
-
The decoder is fed encoded visible patches as well as mask tokens. The mask token just like in BERT, is a “shared learned vector that indicates the presence of a missing patch to be predicted.” Positional embeddings are added to all tokens in the decoder input so that the mask tokens have information about their spatial location in the image. The decoder is used in pre-training to perform image reconstructions after which it can be removed while applying the encode representations to downstream tasks. This enables creation of independent encoder decoder designs. The authors employ a lightweight decoder such that it has <10% of per token computation when compared to the encoder. Due to this, although the decoder has to process the complete set of tokens, its lightweight nature creates computational benefits.
-
The output of the decoder is a vector of pixel values that are projected and reshaped to form the image. The loss function minimizes the MSE between original and reconstructed images in the pixel space.
-
Note that the loss is computed only on the masked patches which was due to empirical observations.
Evaluation
-
They perform self-supervised learning on the ImageNet-1K and then supervised training. Representations are evaluated using end-end finetuning and linear probing. Note that end-end fine tuning is tuning all blocks, partial finetuning is tuning last several layers while freezing others and linear probing does not involve tuning any blocks.
-
They observe that optimal masking ratios are high compared to BERT (15%), and 75% is good for linear probing as well as finetuning.
-
The model infers missing patches to produce different but plausible outputs which implies that it has semantic understanding of the scene and its objects that cannot be naively extrapolated by lines or textures. This is an evidence of the efficacy of the learned representations. The method aims to remove random patches that most likely do not form semantic segments.
-
The authors observe that decoder depth is crucial for linear probing when compared to fine-tuning. They explain that this is because of the differences between pixel reconstruction task and recognition. In an autoencoder, the last several layers are specialized for reconstruction and are not as relevant for recognition. A deep decoder has more layers to account for the reconstruction while having more general latent representations. In fine-tuning, last few layers of the autoencoder can be tuned anyway to the downstream recognition task, making decoder depth not as influential.
-
As mentioned earlier, the authors don’t use mask tokens in the encoder because they observe that accuracy drops by 14% when they are used in the encoder. They assert that this is due to the consequential domain gap between training and inference. During training the encoder sees a large amount of mask tokens which is absent during inference in uncorrupted images. When mask tokens are removed, the encoder always sees real patches maintaining uniformity. This also has computational advantages during training.
-
They also observe that representation quality improves when normalized pixel values are used for reconstruction i.e. mean and standard deviation of all pixels in a patch is used to normalize the patch. The per-patch normalization enhances contrast locally implying that model likes high-frequency components.
-
When the authors use visual tokens as reconstruction targets like in BEiT, they don’t see any advantage vs normalized pixels thus deeming tokenization unnecessary. They use DALL-E dVAE tokenizer for this experiment replicating BEiT. In addition, not having to pre-train dVAE reduces need for additional data and computational overhead. Possibly having the dVAE has some correlation to the difficulty BEiT faces in pixel reconstruction(?) Using dVAE tokens was seen to be better than using unnormalized pixels but using normalized pixels was seen to be same as using tokens over all the cases tested.
-
For augmentation, they only cropping. They see that color jittering degrades results and is not too dependent on augmentation compared to contrastive learning techniques such as SimCLR and BYOL. This might be due to the random masking playing the role of data augmentation since the masks are different at each iteration, leading to “new” data samples.
-
Saturation is not observed for linear probing even at 1600 epochs pointing to scalability, unlike contrastive learning techniques. Note that MAE encoder sees only 25% of patches per epoch while contrastive techniques sees 200% of patches owing to data augmentation dependency.
-
To adapt their model with ViT backbone to object detection (Mask R-CNN), they divide the stack of transformer blocks into 4 subsets and apply convolutions to up/down-sample intermediate feature maps for producing different scales. These multi-scale maps are provided as base for FPN.